Глава 2
Основные концепции систем реального времени
Системы реального времени отличаются возможностью наступления серьёзных последствий в случае невыполнения ими в процессе работы не только логических, но и временных требований. Существует два типа систем реального времени: системы мягкого реального времени и системы жесткого реального времени. В системах мягкого реального времени задачи должны выполняться быстро, насколько это возможно, но конкретное время выполнения не задано. В системах жесткого реального времени задачи должны выполняться не только правильно, но и в срок. Большинство систем реального времени представляют собой комбинацию систем этих двух типов. Применение систем реального времени покрывает широкий спектр задач. Большинство систем реального времени представляют собой встраиваемые системы. Это означает, что компьютер встроен в некий прибор и не выглядит компьютером для пользователя. Примеры встраиваемых систем:
| Управление процессами: | ||
| Производство пищевых продуктов | ||
| Химические производства | ||
| Автотранспорт: | ||
| Системы управления двигателем | ||
| Антиблокировочные тормозные системы | ||
| Офисная автоматика | ||
| Факсимильные аппараты | ||
| Копиры | ||
| Компьютерная периферия | ||
| Принтеры | ||
| Терминалы | ||
| Сканеры | ||
| Модемы | ||
| Роботы | ||
| Аэрокосмические системы | ||
| системы управления полётом | ||
| системы управления вооружением | ||
| системы управления реактивными двигателями | ||
| Бытовая техника | ||
| Микроволновые печи | ||
| Посудомоечные машины | ||
| Стиральные машины | ||
| Термостаты | ||
Приложения систем реального времени проектировать сложнее, чем обычные приложения.
Данная глава описывает основные концепции систем реального времени.
2.00 Системы типа "суперпетля"
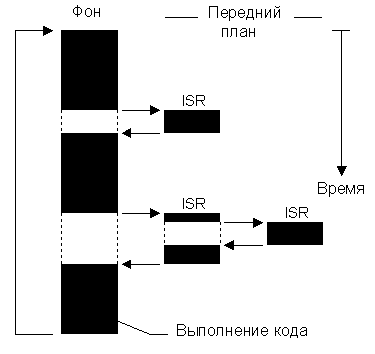
Малые системы небольшой сложности проектируются, в основном, как показано на рисунке 2-1. Такие системы называются системами типа "суперпетля". Приложение представляет собой бесконечный цикл, в котором для выполнения требуемых задач (на заднем плане, также называемом уровнем задач) вызываются необходимые модули (то есть функции). Асинхронные события обрабатываются при помощи подпрограмм обработки прерываний, ISR (на переднем плане, также называемом уровнем прерываний). Критичные операции должны выполняться в ISR, чтобы иметь гарантированное время выполнения. Из-за этого ISR имеют тенденцию становиться длиннее, чем должны быть. Также, информация для фоновых задач, становящаяся доступной в результате работы ISR, не может быть обработана, пока не закончится текущий оборот бесконечного цикла выполнения приложения. Это называется откликом уровня задач. Худший случай для времени отклика уровня задач зависит от того, насколько быстро выполняется этот бесконечный цикл. Так как время выполнения кода обычно не постоянно, то время успешного выполнения одного оборота суперпетли ничем не определено, недетерминировано. Более того, если код модифицируется, это тоже оказывает влияние на величину отклика уровня задач.
2.01 Критическая секция кода
Критическая секция кода - это фрагмент кода, который нельзя разделять при выполнении. Если код критической секции начал выполняться, его нельзя прерывать. Чтобы обеспечить это, обычно перед выполнением критической секции кода прерывания запрещают, а после выполнения снова разрешают (см. также Разделяемые ресурсы).
2.02 Ресурс
Ресурс - это любая сущность, используемая задачей. Это, например, устройства ввода-вывода, такие как принтер, клавиатура, дисплей, и т.д., или переменная, структура, массив и т.п.2.03 Разделяемый ресурс
Разделяемый ресурс - это ресурс, который может быть использован более чем одной задачей. Во избежание повреждения данных каждая задача должна получать исключительный доступ к разделяемому ресурсу. Такой подход называется взаимным исключением и обсуждается в разделе 2.19, "Взаимное исключение".2.04 Многозадачность
Многозадачность - это процесс переключения процессора между несколькими задачами. Многозадачная система похожа на систему, основанную на "суперпетле", но с несколькими фонами. Многозадачность увеличивает использование процессора, а также обеспечивает возможность модульной конструкции приложения. Один из самых важных аспектов многозадачности состоит в том, что она позволяет программисту управлять сложностью, присущей приложениям реального времени. К тому же, при использовании многозадачности прикладные программы проще в написании и поддержке .2.05 Задача
Задача, или поток, - это просто программа, полагающая, что только она одна выполняется на процессоре. Процесс проектирования приложения реального времени предполагает разделение всей задачи на части, каждая из которых ответственна за свою долю работы. Каждой задаче назначается приоритет, её собственный набор регистров процессора, и её область стека, как показано на рисунке 2-2.
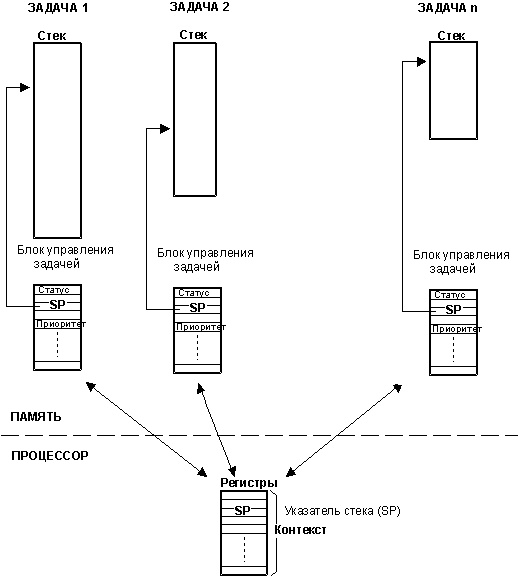 Рис. 2-2, многозадачность.
Рис. 2-2, многозадачность.
Каждая задача может находиться в одном из пяти состояний: сна, готовности, выполнения, ожидания события, или прерывания (см. рис. 2-3). Состояние сна соответствует задаче, которая находится в памяти, но не сделана доступной многозадачному ядру. Задача находится в состоянии готовности, когда она может выполняться, но её приоритет меньше, чем у выполняющейся в данный момент задачи. Задача находится в состоянии выполнения, когда она управляет процессором. Задача находится в состоянии ожидания события, когда ей требуется появление события (такого как завершение операции ввода-вывода, освобождение разделяемого ресурса, появление тактирующего импульса, истечение времени, и т.п.). И, наконец, задача находится в состоянии прерывания, когда во время её выполнения возникло прерывание и процессор занят процедурой его обработки. Рисунок 2-3 также показывает функции переключения состояния задачи, обеспечиваемые микроСи/ОС-II
. 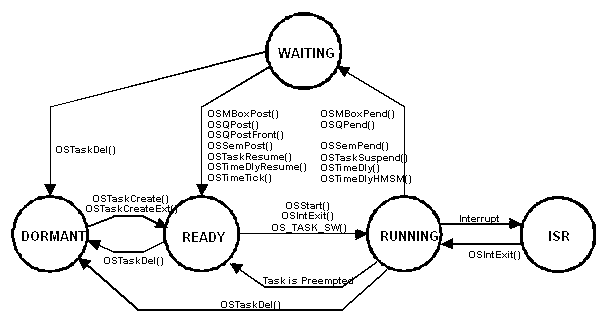
Рисунок 2-3, состояния задачи.
2.06 Переключение контекста (переключение между задачами)
Когда многозадачное ядро решает запустить следующую задачу, оно просто сохраняет контекст (содержимое регистров процессора) текущей задачи в её стеке - области хранения контекста задачи, см. рисунок 2-2. Затем контекст следующей задачи восстанавливается из области его хранения, после чего продолжается выполнение кода задачи, чей контекст загружен. Такая последовательность действий называется переключением контекста, или переключением между задачами. Переключение контекста приводит к дополнительным затратам процессорного времени, тем большим, чем больше регистров у процессора. Время, требуемое для переключения контекста, определяется количеством регистров, которые нужно сохранить и восстановить.2.07 Ядро
Ядро - это часть многозадачной системы, ответственная за управление задачами (или за распределение времени процессора) и межзадачное взаимодействие. Основной сервис, предоставляемый ядром - это переключение контекста. Использование ядра реального времени упрощает проектирование систем, так как позволяет осуществить разделение приложения на несколько задач, управляемых ядром. Ядро повышает требования системы к аппаратному обеспечению, так как требуется дополнительное ПЗУ для его хранения, дополнительное ОЗУ для структур данных ядра, и, что более важно, каждая задача требует пространство для её собственного стека, который быстро поглощает ОЗУ. Ядро также требует процессорного времени (обычно 2-5%).2.08 Диспетчер задач
Диспетчер задач - это часть ядра, ответственная за определение того, какая задача будет запущена следующей. Большинство ядер реального времени используют для этого систему приоритетов. Каждой задаче в зависимости от её важности назначается свой приоритет. Таким образом, в случае ядра реального времени с системой приоритетов управление процессором всегда будет получать готовая к выполнению задача с наивысшим приоритетом. Когда именно задача с наивысшим приоритетом получит управление, будет, конечно, определяться типом используемого ядра. Ядра, управляемые системой приоритетов, бывают двух типов - невытесняющие и вытесняющие.2.09 Ядро невытесняющего типа
Ядро невытесняющего типа подразумевает, что задача сама уступает управление процессором другой задаче. Чтобы обеспечить видимость параллельной работы задач этот процесс должен происходить достаточно часто. Невытесняющее управление также называется кооперативной многозадачностью, так как задачи взаимодействуют друг с другом в процессе разделения времени процессора. Асинхронные события всё так же обрабатываются подпрограммами обработки прерываний (ISR). Запустившаяся подпрограмма обработки прерывания может сделать задачу с высоким приоритетом готовой к выполнению, но по завершении ISR управление возвращается прерванной задаче. Новая высокоприоритетная задача запустится только тогда, когда текущая задача уступит ей процессор. 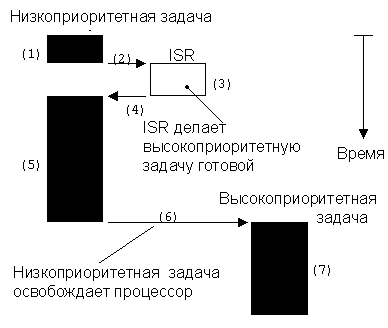
Рисунок 2-4, невытесняющее ядро.
2.10 Вытесняющее ядро
Ядро вытесняющего типа применяется, когда особенно важно время отклика системы на события. Поэтому микроСи/ОС и большинство коммерческих ядер реального времени - это ядра вытесняющие. Управление процессором всегда отдано задаче с наивысшим приоритетом. Когда появляется готовая к выполнению задача с высшим приоритетом, текущая задача вытесняется (приостанавливается), и управление немедленно получает задача с высшим приоритетом. Если задачу с высшим приоритетом подготавливает подпрограмма обработки прерывания (ISR), то когда ISR завершается, прерванная задача приостанавливается, а управление получает новая высокоприоритетная задача. Это показано на рисунке 2-5.
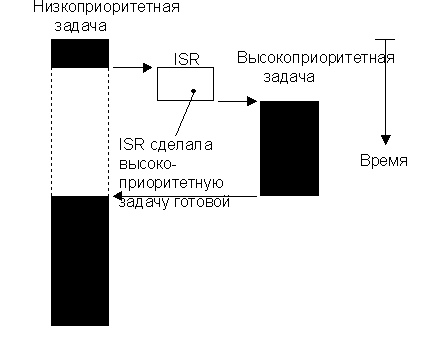
Рисунок 2-5, вытесняющее ядро.
В случае вытесняющего ядра выполнение высокоприоритетной задачи вполне предсказуемо. Вы вполне можете определить, когда задача с наивысшим приоритетом получит управление. Применение ядра вытесняющего типа также уменьшает время отклика уровня задач.
В случае вытесняющего ядра в коде приложения нельзя делать вызовы нереентерабельных
функций, за исключением случаев, когда исключительный доступ к ним гарантирован
применением семафоров взаимного исключения, так как в таком случае задачи как
низкого, так и высокого приоритета могут вызывать общие функции. Если задача
с высшим приоритетом вытесняет задачу с низшим приоритетом, вызвавшую нереентерабельную
функцию, может произойти повреждение данных.
Подводя итог обзора свойств ядра вытесняющего типа, можно сказать следующее:
вытесняющее ядро всегда выполняет готовую задачу с наивысшим приоритетом. Прерывание
вытесняет задачу. После прерывания ядро снова запускает задачу с наивысшим приоритетом
(а не прерванную задача). Время отклика уровня задач в этом случае оптимально
и детерминировано. МикроСи/ОС-II - ядро вытесняющего типа.
2.11 Реентерабельность, или повторная входимость
Реентерабельная, или повторно входимая функция - это функция, которая может быть использована более чем одной задачей без риска потери данных. Реентерабельная функция может быть в любое время прервана и продолжена позже без потерь данных. Реентерабельные функции либо используют локальные переменные (например, регистры процессора или переменные в области стека), либо защищают свои данные, размещённые в глобальных переменных. Пример реентерабельной функции приведен в листинге 2.1.void strcpy(char *dest, char *src)
{
while (*dest++ = *src++) {
;
}
*dest = NUL;
}
Листинг 2.1, реентерабельная функция.
Так как копии аргументов strcpy() располагаются в стеке задачи, strcpy() может использоваться несколькими задачами без риска взаимного повреждения указателей.
Пример нереентерабельной функции приведён в листинге 2.2. swap() - это функция, которая просто меняет друг с другом содержимое её аргументов. Предположим, что используется вытесняющее ядро, прерывания разрешены, а переменная Temp объявлена как глобальная:
int Temp;
void swap(int *x, int *y)
{
Temp = *x;
*x = *y;
*y = Temp;
}Листинг 2.2, нереентерабельная функция.
Программист сделал возможным вызов функции swap() любой задачей. Рисунок 2-6 показывает, что может произойти в случае, если низкоприоритетная задача была прервана при выполнении кода функции swap() F2-6(1). Заметьте, что Temp сейчас содержит 1. Подпрограмма обработки прерывания (ISR) делает задачу с высоким приоритетом готовой к исполнению, и, после завершения ISR ядро переключает процессор на выполнение этой задачи F2-6(3). Высокоприоритетная задача присваивает переменной Temp значение 3, и меняет содержимое собственных аргументов вполне корректно (таким образом, z равно 4, а t равно 3). Затем высокоприоритетная задача отдаёт управление низкоприоритетной F2-6(4) путём вызова специального сервиса ядра, приостанавливающего её выполнение на один период системного таймера (обсуждается позже). Низкоприоритетная задача продолжает выполнение F2-6(5). Заметьте, что в данный момент переменная Temp содержит значение 3 ! При продолжении низкоприоритетной задачи переменной y присваивается значение 3, а не 1.
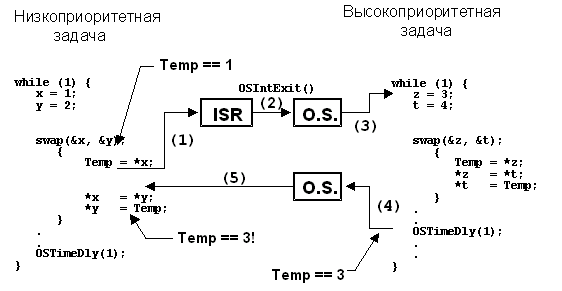
Рис. 2-6, нереентерабельная функция.
Этот пример довольно прост и в данном случае очевидно, как сделать код повторно входимым. Конечно, другие ситуации не так просты. Ошибка, вызванная нереентерабельной функцией, может не проявиться на этапе тестирования, но она весьма вероятно проявится после сдачи проекта! Нужно быть осторожным при использовании нереентерабельных функций.
Мы можем сделать swap() повторно входимой, используя следующие приёмы:
а) объявить Temp локально в swap()
б) запретить прерывания перед и разрешить
после использования функции
с) использовать семафор (обсуждается позже)
Если прерывание появится либо до, либо после функции, она отработает правильно для обеих задач.
2.12 Круговая диспетчеризация, или Раунд-Робин
Когда две или более задач имеют одинаковый приоритет, ядро позволяет одной задаче работать определённое количество времени, называемое квантом, а затем выбирает другую задачу. Это называется также разделением времени между задачами, или таймслайсингом. Ядро передаёт управление следующей задаче, если:
а) текущей задаче нечего делать в её квант времени, или
б) текущая задача завершилась до конца её кванта времени.
На данный момент микроСи/ОС-II не поддерживает круговую диспетчеризацию. Каждая задача в приложении должна иметь уникальный уровень приоритета.
2.13 Приоритет задачи
Каждой задаче назначается приоритет, тем высший, чем задача важнее.
2.14 Статические приоритеты
Приоритет задачи называется статическим, если он не меняется всё время выполнения приложения. Таким образом, во время компиляции задаче присваивается фиксированный приоритет. В системе со статическими приоритетами все задачи и их временные ограничения известны ещё на этапе компиляции.
2.15 Динамические приоритеты
Приоритет задачи называется динамическим, если он может быть изменён во время выполнения кода. Для ядра реального времени система динамических приоритетов является желательной во избежание инверсии приоритетов.
2.16 Инверсия приоритетов
Инверсия приоритетов является существенной проблемой в системах реального времени. Сценарий возникновения инверсии приоритетов показан на рис. 2-7. Задача №1 имеет приоритет высший, нежели задача №2, которая, в свою очередь, имеет приоритет высший, нежели задача №3. На данный момент задачи №1 и №2 ожидают возникновения некого события, поэтому выполняется задача №3 F2-7(1). В некоторый момент задача №3 завладевает семафором (см. раздел 2.18, Семафоры), который необходим для использования некоторого разделяемого ресурса F2-7(2). Задача №3 работает с затребованным ресурсом F2-7(3) до тех пор, пока её не вытеснит задача с высшим приоритетом, например, задача №1 F2-7(4). Через некоторое время задаче №1 также может потребоваться обратиться к данному разделяемому ресурсу F2-7(5). Так как он занят задачей №3, задаче №1 придётся подождать, пока задача №3 освободит семафор. Ядро замечает, что семафор занят, приостанавливает задачу №1, и снова запускает задачу №3 F2-7(6), чтобы она смогла отработать и освободить семафор. Задача №3 продолжает свою работу, но вытесняется задачей №2, так как событие, которого ждала задача №2, произошло F2-7(7). Задача №2 обрабатывает поступившее событие F2-7(8), и, отработав, отдаёт управление процессором обратно задаче №3 F2-7(9). Задача №3 заканчивает работу с разделяемым ресурсом F2-7(10) и освобождает семафор F2-7(11). По освобождении семафора ядро запускает высокоприоритетную задачу №1, ждущую доступа к разделяемому ресурсу. Задача №1 овладевает семафором и получает доступ к необходимому ресурсу F2-7(12).
Получается, что в рассмотренной ситуации приоритет задачи №1 как бы уменьшился ниже приоритета задачи №3, так как третья задача обладала необходимым первой задаче ресурсом. Положение еще ухудшилось, когда вторая задача вытеснила третью, что еще больше задержало выполнение задачи №1, имеющей наивысший приоритет.
Положение дел можно исправить, если сделать приоритет задачи №3 выше остальных, требующих данного ресурса на время её работы с ним, и вернуть прежний после освобождения ресурса. Многозадачное ядро реального времени должно, несомненно, позволять динамически изменять приоритеты работающих задач, помогая тем самым избегать инверсии приоритетов. Однако, что если задача №3 успеет завершить доступ к ресурсу до того, как её вытеснит задача №1, а затем задача №2? В таком случае, повышая приоритет задачи №3, мы просто теряем процессорное время. Что действительно необходимо для того, чтобы избежать инверсии приоритетов - ядро, которое меняет приоритеты задач автоматически. Это называется наследованием приоритетов, и, к сожалению, микроСи/ОС-II не обладает таким свойством. Существуют, конечно, коммерческие ядра, которые таким свойством обладают.
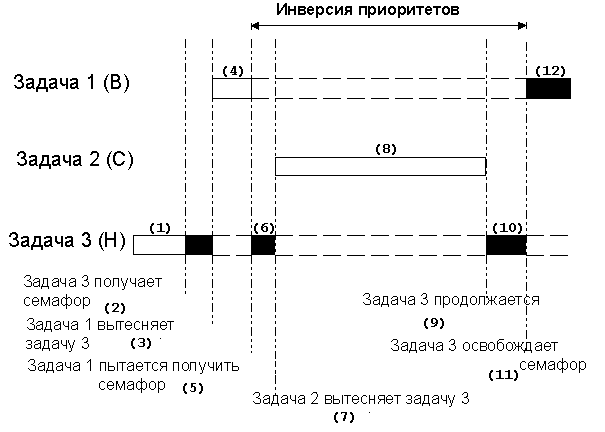
Рис. 2-7, проблема инверсии приоритетов.
Рисунок 2-8 иллюстрирует работу системы в случае, если ядро поддерживает наследование приоритетов. Как и в предыдущем примере, задача №3 выполняется F2-8(1), затем запрашивает семафор, чтобы обратиться к разделяемому ресурсу F2-8(2). Задача №3 получает доступ к ресурсу F2-8(3), а затем вытесняется задачей №1 F2-8(4). Задача №1 выполняется F2-8(5), а затем пытается запросить семафор F2-8(6). Ядро видит, что задача №3 обладает этим семафором, но имеет низший, чем у задачи №1, приоритет. В этом случае, ядро повышает приоритет задачи №3 до приоритета задачи №1. Затем ядро переключается на выполнение задачи №3, которая продолжает работу с занятым ею ресурсом F2-8(7). Через некоторое время задача №3 освобождает семафор F2-8(8). В этот момент ядро понижает приоритет задачи №3 до его первоначального уровня, и передаёт семафор задаче №1, которая теперь может свободно продолжать свою работу с разделяемым ресурсом F2-8(9). Когда задача №1 завершает выполнение F2-8(10), управление получает задача со средним приоритетом F2-8(11), то есть задача №2. Заметьте, что задача №2 была готова к выполнению всё время, начиная с F2-8(3) и заканчивая F2-8(10), без всякого результата. Это тоже некий уровень инверсии приоритетов, который уже никак нельзя избежать.

Рис. 2-8, Ядро, которое поддерживает наследование приоритетов.
2.17 Присвоение приоритетов
Присвоение задачам приоритетов является непростым делом в силу сложной природы систем реального времени. В большинстве систем не все задачи являются критичными ко времени их выполнения. Некритичным задачам обычно присваивается низкий приоритет. К большинству систем предъявляются требования как жесткого, так и мягкого реального времени. В системах мягкого реального времени задачи выполняются быстро насколько это возможно, но они не обязаны завершаться за определённое время. В системах жесткого реального времени задачи должны выполняться в срок, за предопределённое время.
Интересная техника, называемая пропорциональной диспетчеризацией может применяться для назначения задачам приоритетов пропорционально частоте их выполнения. Проще говоря, задаче с большим темпом обращения к процессору присваивается высший приоритет (см. рис. 2-9).
Пропорциональная диспетчеризация
исходит из следующих предположений:
1. Все задачи периодичны (происходят регулярно).
2. Задачи не синхронизированы друг с другом, не разделяют ресурсов, и не обмениваются данными.
3. Процессор всегда выполняет задачу с наивысшим приоритетом, то есть должно использоваться ядро
вытесняющего типа.
Базовая теорема пропорциональной диспетчеризации утверждает, что для набора из n задач все требования жесткого реального времени выполняются, если соблюдено следующее неравенство:
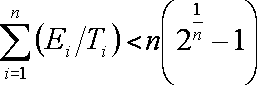
Ei - наибольшее время выполнения задачи i
Ti - период выхода задачи i на процессор
Другими словами, Ei/Ti - доля времени процессора, необходимого задаче i. Таблица 2.1 содержит значения величины n(2**1/n -1) в зависимости от числа задач n. Значение этого выражения для бесконечно большого числа задач представляется в виде ln 2, или 0.693. Это означает, что для того, чтобы обеспечить все требования жесткого реального времени в системе с пропорциональной диспетчеризацией необходимо, чтобы загрузка процессора критичными ко времени исполнения задачами была меньше 70 процентов! Заметьте, что при этом в системе могут выполняться и некритичные ко времени выполнения задачи, а общая загрузка процессора вполне может достигать 100 процентов. Замечу, что использование 100 процентов времени процессора не является желаемой целью, так как не позволяет расширять дизайн системы. Как правило, вы должны использовать 60-70 процентов процессорного времени.
|
|
|
|
|
|
|
|
|
|
|
|
|
... |
... |
|
∞ |
|
Таблица 2.1
В случае пропорциональной диспетчеризации предполагается, что самая часто выполняемая задача имеет наивысший приоритет. Однако, в некоторых случаях самая часто выполняемая задача может не быть самой важной. Специфика собственно самого приложения является основанием для присвоения приоритетов. Методика пропорциональной диспетчеризации - это, конечно, хороший старт.
2.19 Взаимное исключение
Простейшим способом взаимодействия задач друг с другом является работа с разделяемыми структурами данных. Это особенно легко, если все задачи располагаются в едином адресном пространстве. Таким образом, задачи могут ссылаться на глобальные переменные, указатели, буферы, связанные списки, кольцевые буферы и т.п. Хотя разделяемые данные упрощают обмен информацией, вы должны обеспечить исключительный доступ задачи к данным во избежание столкновений и повреждения данных. Самые общие методы получения исключительного доступа к разделяемым ресурсам - это:
а) запрещение прерываний
б) проба - и - установка
в) отключение диспетчеризации
г) использование семафоров
2.19.01 Взаимное исключение, запрещение и разрешение прерываний
Простейший и быстрейший путь получения исключительного доступа к разделяемым ресурсам - запрещение и разрешение прерываний, как показано в псевдокоде в листинге 2.3.
Запретить прерывания; Осуществить доступ (чтение/запись переменных); Разрешить прерывания;
Листинг 2.3, запрет/разрешение прерываний.
МикроСи/ОС-II использует эту технику (как и многие, если не все ядра) для доступа к собственным переменным и структурам данных. МикроСи/ОС-II предоставляет два макроса для запрещения и разрешения прерываний из программы на Си - это OS_ENTER_CRITICAL() и OS_EXIT_CRITICAL() соответственно (см. раздел 8.03.02, OS_CPU.H, OS_ENTER_CRITICAL() и OS_EXIT_CRITICAL()). Эти макросы используются парами, как показано в листинге 2.4.
void Function (void)
{
OS_ENTER_CRITICAL();
.
. /*Здесь возможен доступ к разделяемым данным*/
.
OS_EXIT_CRITICAL();
}
Листинг 2.4, Использование макросов микроСи/ОС-II для запрещения/разрешения прерываний.
Такой подход нужно использовать осторожно и не запрещать прерывания надолго, чтобы не ухудшать время реакции системы на прерывания. Этот метод пригоден, если копируется или изменяется всего лишь несколько переменных. Также, это единственный способ обмена данными между задачей и подпрограммой обработки прерывания (ISR). В любом случае, прерывания должны быть запрещены минимально возможное время.
2.19.02 Взаимное исключение, Проба - и - Установка
Если ядро не используется, две функции могут "договориться", что
перед доступом к ресурсам они должны проверять некую глобальную переменную,
и, если она равна нулю, то доступ считается разрешённым. При этом первая из
функций, получившая доступ, устанавливает эту переменную в единицу. Это обычно
называется операцией Проба - и - Установка (Test-And-Set, TAS).
Эта операция либо должна производиться неразделимо самим процессором, либо
нужно запретить прерывания на время этой операции, как показано в листинге
2.5.
Запретить прерывания;
Если ('Переменная доступа'== 0){
Установить переменную в 1;
Разрешить прерывания;
/*Доступ разрешён*/
Произвести доступ к ресурсам;
Запретить прерывания;
Установить переменную доступа в ноль;
Разрешить прерывания;
} иначе {
Разрешить прерывания;
/*Доступ запрещён, попробуйте позже*/
}
Листинг 2.5, доступ к ресурсу с использованием операции TAS.
Некоторые процессоры (например, семейство 68000) имеют инструкцию TAS, реализованную аппаратно.
2.19.03 Взаимное исключение, блокировка диспетчеризации
Если задача не разделяет переменных или структур данных с подпрограммами обработки прерываний (ISR), то можно блокировать/разблокировать диспетчеризацию (см. раздел 3.06, Блокировка и разблокировка диспетчеризации), как показано в листинге 2.6 на примере микроСи/ОС-I. В этом случае две задачи могут разделять данные без опасности возникновения столкновений. Нужно также заметить, что когда диспетчер заблокирован, прерывания разрешены, и, если прерывание возникнет во время прохождения программой критической секции, то немедленно начнёт выполняться ISR. После отработки ISR управление вернётся к прерванной задаче, даже если ISR сделала готовой задачу с высшим приоритетом. После вызова OSSchedUnlock() будет проверено наличие высокоприоритетных задач, и, если они есть, будет произведёно переключение контекста. Хотя этот метод хорошо работает, следует избегать блокировки диспетчеризации, так как такой подход частично лишает смысла применение ядра как такового. Лучше использовать следующий метод.
void Function (void)
{
OSSchedLock();
.
./*Здесь доступ к разделяемым данным разрешён, прерывания разрешены */
.
OSSchedUnlock();
}
Листинг 2.6, доступ к данным с блокировкой диспетчеризации.
2.19.03 Взаимное исключение, семафоры
Семафоры были изобретены Эдгзером Дейкстрой в середине 1960-х. Семафоры - это механизм, предоставляемый большинством многозадачных ядер. Семафоры применяются чтобы:
а) управлять доступом к разделяемым ресурсам;
б) сигнализировать наступление события;
в) позволять двум задачам синхронизировать их деятельность.
Семафор - это ключ, которым должна овладеть задача, чтобы продолжить выполнение. Если семафор уже используется, запрашивающая задача приостанавливается, пока семафор не освободится. Другими словами, задача говорит: "Мне нужен ключ. Если кто-то его уже взял, я подожду".
Есть два типа семафоров: двоичные и счётные. Как видно из названия, двоичный семафор может принимать только два значения - 0 или 1. Счётный семафор может принимать значения в диапазоне от 0 до 255, 65535 или 4294967295, в зависимости от того, семафор какой разрядности используется - 8, 16 или 32 бит соответственно. Это значение зависит от того, какое ядро используется. Также, наряду со значением семафора, ядру нужно хранить список задач, ждущих его доступности. Существуют три основные операции, которые можно производить с семафорами - это Инициализация INITIALIZE (или CREATE), Ожидание WAIT (или PEND) и Освобождение SIGNAL (или POST).
Начальное значение семафора задаётся при его создании. Список задач, ожидающих данный семафор, исходно должен быть пуст.
Задача, желающая обладать семафором, производит операцию WAIT. Если семафор доступен, то есть его значение больше 0, оно уменьшается на единицу, а задача продолжает выполнение. Если значение семафора равно 0, задача, производящая операцию WAIT, помещается в список задач, ожидающих данный семафор. Многие ядра позволяют также определять промежуток времени (тайм-аут), по истечении которого задача запускается вновь, причём ей сообщается код возврата, указывающий на истечение тайм-аута.
Задача освобождает семафор, производя операцию SIGNAL. Если нет задач, его ожидающих, значение семафора увеличивается на единицу. Если такие задачи есть, его значение не изменяется, а запускается одна из ожидающих задач. В зависимости от конкретной организации ядра, следующей получившей семафор задачей будет либо
а) задача с наивысшим приоритетом среди ожидающих, либо
б) задача, затребовавшая семафор первой (First In-First Out).
Некоторые ядра позволяют задать метод выбора задач из списка при инициализации семафора. МикроСи/ОС-II поддерживает только первый метод. Если ожидающая задача имеет высший приоритет, чем текущая, освобождающая семафор, произойдёт переключение контекста, высокоприоритетная задача запустится, а низкоприоритетная будет приостановлена.
Листинг 2.7 показывает, как производится доступ к данным с использованием семафора (на примере микроСи/ОС-II). Любая задача, требующая доступа к разделяемому ресурсу, должна сначала вызвать OSSemPend(), а после завершения работы с ресурсом должна вызвать OSSemPost(). Обе эти функции будут описаны позже. Сейчас же заметьте, что семафор - это объект, который должен быть инициализирован перед использованием, причём для процедуры взаимного исключения он инициализируется значением 1. Применение семафоров не влияет на время реакции системы на прерывания, поэтому если высокоприоритетная задача появляется во время доступа к разделяемым с применением семафора данным, она немедленно запускается.
OS_EVENT *SharedDataSem;
void Function (void)
{
INT8U err;
OSSemPend(SharedDataSem, 0, &err);
.
./*Здесь доступ к разделяемым данным разрешён, прерывания разрешены */
.
OSSemPost(SharedDataSem);
}
Листинг 2.7, доступ к данным с применением семафора.Семафоры особенно удобны, когда задачам необходимо разделять устройства ввода-вывода. Представьте, что могло бы произойти, если бы двум задачам было позволено отправлять символы на принтер одновременно. Принтер печатал бы чередующиеся данные. Например, если первая задача попыталась бы напечатать "I am task#1!", а вторая - "I am task#2!", то на выходе могло получиться что-нибудь вроде:
I Ia amm t tasask k#1 #!2!
Чтобы этого избежать, необходимо использовать [двоичный] семафор, то есть инициализировать его в 1. Правила просты - перед доступом к принтеру задача должна предварительно овладеть этим семафором. На рисунке 2-9 показаны задачи, соревнующиеся за обладание семафором, чтобы получить право исключительного доступа к принтеру. Семафор символически показан в виде ключа, который задача должна получить.
В приведённом выше примере подразумевается, что задачи должны знать о существовании семафора, управляющего доступом к ресурсу. Бывают также ситуации, когда семафор лучше инкапсулировать. В этом случае задача не будет знать, что для доступа к ресурсу используется семафор. Например, последовательный RS-232 порт используется несколькими задачами для посылки команд и приёма ответов присоединённого к другому концу линии устройства. Диаграмма работы показана на рисунке 2-10.

Рис. 2-9, использование семафора для получения доступа к принтеру.
Функция CommSendCmd() имеет три аргумента: это ASCII - строка, содержащая команду, указатель на строку, в которую будет помещён ответ удалённого устройства, и, наконец, величина тайм-аута, на случай, если устройство не ответит за данный промежуток времени. В листинге 2-8 приведён псевдокод такой функции.
INT8U CommSendCmd(char *cmd, char *response, INT16U timeout)
{
Овладеть семафором порта;
Послать команду устройству;
Ожидать ответа(timeout);
если(таймаут вышел) {
Освободить семафор;
Возвратить код ошибки;
} иначе {
Освободить семафор;
Возвратить код отсутствия ошибки;
}
}Листинг 2-8, инкапсуляция семафора.
Каждая задача, желающая послать команду удалённому устройству, должна вызвать эту функцию. Предполагается, конечно, что семафор установлен в 1 (т.е. сделан доступным) процедурой инициализации коммуникационного драйвера. Первая вызвавшая функцию CommSendCmd() задача овладеет семафором и приступит к посылке команды и ожиданию ответа. Если другая задача попытается послать команду, пока порт занят, она будет приостановлена до освобождения семафора. По сути, эта вторая задача производит вызов самой обычной функции, которая не возвратится в исходную программу, пока не выполнит свою работу. Когда первая задача освободит семафор, его захватит вторая задача, которой с этого момента порт становится доступным.
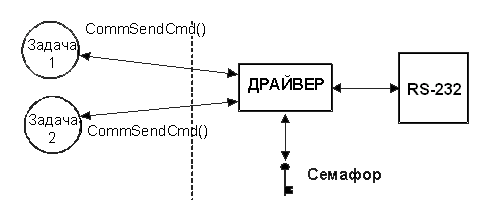
Рис. 2-10, скрытый семафор.
Счётные семафоры применяются, когда ресурс может использоваться более чем одной задачей одновременно. Например, счётный семафор может быть использован в управлении пулом буферов, как это показано на рис. 2-11. Предположим, что исходно пул содержит 10 буферов. Задача может получить буфер, запросив его у менеджера, вызывая BufReq(). Если буфер больше не нужен, задача может вернуть его обратно, вызывая BufRel(). Псевдокод этих функций приведён в листинге 2.9.
BUF *BufReq(void)
{
BUF *ptr;
Овладеть семафором;
Запретить прерывания;
ptr = BufFreeList;
BufFreeList = ptr->BufNext;
Разрешить прерывания;
Возвратить(ptr);
}
void BufRel(BUF *ptr)
{
Запретить прерывания;
ptr->BufNext = BufFreeList;
BufFreeList = ptr;
Разрешить прерывания;
Освободить семафор;
}
Листинг 2.9, применение счётного семафора для управления буферами.
Так как имеется только 10 буферов, менеджер удовлетворит первые 10 запросов. Когда же они будут исчерпаны, следующая запрашивающая задача будет приостановлена, пока семафор снова не станет доступен. Прерывания запрещаются, чтобы получить исключительный доступ к связанному списку (это довольно быстрая операция). Когда функция закончила работу с выделенным ей буфером, она вызывает BufRel(), чтобы возвратить его менеджеру буферов, который ставит его обратно в список, и только затем освобождается семафор. Инкапсуляция интерфейса менеджера буферов в BufReq() и BufRel() позволяет изолировать вызывающую функцию от деталей реализации этого механизма.
Семафоры иногда применяются неоправданно часто. Использование семафора для доступа к одной простой переменной - почти всегда слишком большой перерасход ресурсов, так как овладевание и освобождение семафора требует ценного процессорного времени. Эту задачу можно достаточно эффективно решить при помощи запрета и разрешения прерываний (см. раздел 2.19.01, Взаимное исключение, запрещение и разрешение прерываний). Предположим, что две задачи разделяют одну 32-разрядную целочисленную переменную, причём первая задача инкрементирует её, а вторая обнуляет. Если разобраться, сколько времени процессор тратит на эти операции, станет ясно, что в данном случае семафор не обязателен. Задачи должны просто запрещать прерывания перед каждой операцией с данной переменной, а затем снова разрешать их. Семафор должен, конечно, применяться в случае переменных с плавающей точкой, при условии, что процессор не может обрабатывать их аппаратно, так как при этом запрещение прерываний может существенно повлиять на время реакции системы.
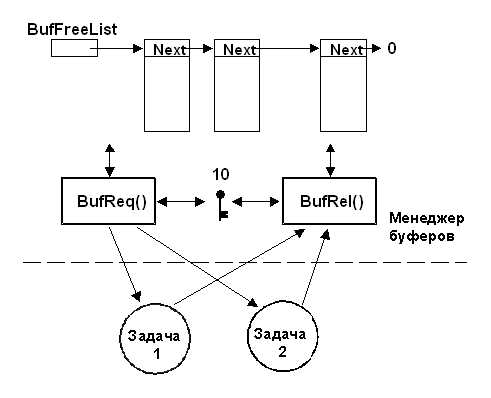
Рис. 2-11, применение счётного семафора.
2.20 Взаимоблокировка
Взаимоблокировка - это ситуация, при которой задачи бесконечно долго ожидают ресурсов, удерживаемых друг другом. Допустим, что задача Т1 получила исключительный доступ к ресурсу Р1, а задача Т2 - к ресурсу Р2. Если при этом задаче Т1 потребуется доступ к ресурсу Р2, а задаче Т2 - к ресурсу Р1, то ни одна из задач не сможет продолжить выполнение, так как они окажутся взаимно заблокированы друг другом. Простейший способ избежать взаимоблокировки задач - это:
а) овладевать всеми ресурсами перед их обработкой;
б) овладевать ресурсами в определённом порядке, и
в) освобождать их в обратном порядке.
Многие ядра позволяют указать величину тайм-аута при затребовании семафора. Такая особенность позволяет избегать взаимоблокировок. Если семафор всё еще не доступен по прошествии определённого времени, запросившая его задача продолжит выполнение. В этом случае задаче должен быть сообщен некий код ошибки, чтобы указать на то, что ресурсом она не обладает. Взаимоблокировки возникают, в основном, в больших многозадачных системах, и реже встречаются во встраиваемых системах.
2.21 Синхронизация
Задача может быть синхронизована с подпрограммой обработки прерывания (ISR) или с другой задачей, не имеющей общих данных, также при помощи семафора, как это показано на рис. 2-12. Заметьте, что в этом случае, семафор изображён как флаг, чтобы показать, что он используется для сигнализирования появления некого события, а не для обеспечения взаимного исключения (в этом случае он изображается в виде ключа). Когда семафор применяется как механизм синхронизации, при инициализации ему присваивается значение 0. Вышеописанный способ синхронизации носит название метода "одностороннего рандеву". Например, некая задача запускает длительную операцию ввода-вывода, а затем ждёт семафора. Когда ввод-вывод заканчивается, подпрограмма обработки прерывания (или другая задача) устанавливает семафор, после чего выполнение задачи продолжается.
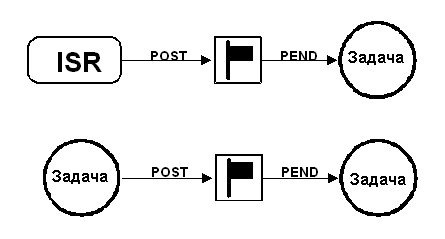
Рис. 2-12, синхронизация задач и ISR.
Если ядро поддерживает счётные семафоры, такой семафор может накапливать события, которые пока не обработаны.
Нужно также заметить, что не только одна, но и несколько задач могут ожидать возникновения некоторого события. В этом случае ядро должно сигнализировать о данном событии либо задаче с наивысшим приоритетом, либо задаче, начавшей ожидание первой. Также, в зависимости от приложения, о возникновении события могут просигнализировать несколько разных задач или ISR.
Две задачи могут взаимно синхронизировать выполнение при помощи двух семафоров, как показано на рисунке 2-13. Такой способ синхронизации носит название метода "двустороннего рандеву".
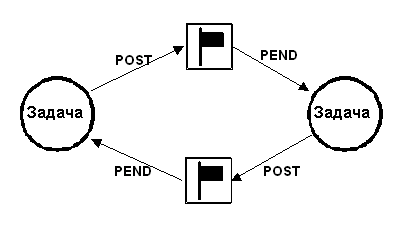
Рис. 2-13, синхронизация двух задач.
Например, пусть две задачи выполняются, как показано в листинге 2.10. Когда первая из них достигнет определённой точки, она подаёт сигнал второй задаче Л2.10(1), после чего ожидает ответа второй задачи Л2.10(2). Аналогично, когда вторая задача достигает определённой точки, она подаёт сигнал первой задаче Л2.10(3), после чего ожидает её ответа Л2.10(4). В данный момент эти две задачи синхронизированы друг с другом. Синхронизация методом двустороннего рандеву могут быть синхронизированы только две отдельные задачи, а не задача и подпрограмма обработки прерывания (ISR), так как ISR не может ждать семафора.
Задача1()
{
for (;;) {
Выполнять;
Просигналить задаче №2; (1)
Ожидать сигнала задачи №2; (2)
Продолжить выполнение;
}
}
Задача2()
{
for (;;) {
Выполнять;
Просигналить задаче №1; (3)
Ожидать сигнала задачи №1; (4)
Продолжить выполнение;
}
}
Листинг 2.10, "двустороннее рандеву".
2.22 Флаги
Флаги применяются в случае необходимости синхронизации задачи с появлением нескольких событий. Задача может быть синхронизирована либо с моментом поступления любого из событий - это дизъюнктивная синхронизация (логическое ИЛИ), либо с моментом, когда произошли все события - это конъюнктивная синхронизация (логическое И). Принципы дизъюнктивной и конъюнктивной синхронизации показаны на рис. 2-14.
Возникновение событий может быть просигнализировано нескольким задачам, как показано на рис. 2-15. События также часто объединяются в группы. В зависимости от реализации ядра группа может состоять из 8-ми, 16-ти или 32-х событий. Задачи и ISR могут устанавливать и сбрасывать любое событие из группы. Задача продолжает выполнение, когда удовлетворены все условия по наличию необходимых ей флагов. Оценка того, какая задача будет продолжать выполнение, производится в момент, когда происходят новые события (т.е. во время операции SET).
Ядро, поддерживающее работу с флагами событий, должно предоставлять необходимые сервисы для того, чтобы УСТАНОВИТЬ (SET) флаг события, СБРОСИТЬ (CLEAR) флаг события и ОЖИДАТЬ (WAIT) появления флага события (конъюнктивно или дизъюнктивно). МикроСи/ОС-II не поддерживает работу с флагами событий.
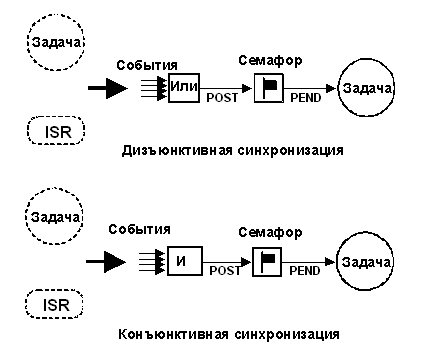
Рис. 2-14, дизъюнктивная и конъюнктивная синхронизация.
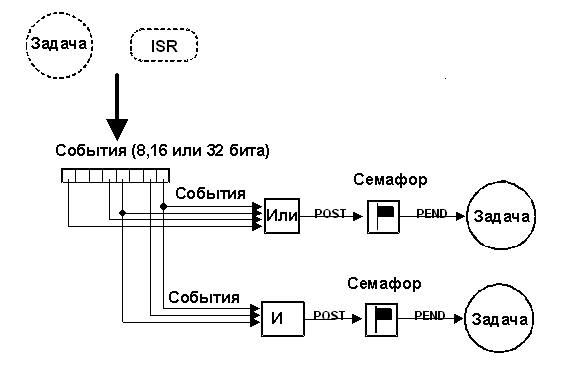
Рис. 2-15, флаги событий.
2.23 Передача информации между задачами
Бывают случаи, когда задаче или ISR необходимо сообщить информацию другой задаче. Такой вид передачи информации называется межзадачным сообщением. Информация между задачами может быть передана либо через глобальные переменные, либо посредством посылки сообщений.
Когда применяются глобальные переменные, каждая задача или ISR должна иметь исключительный доступ к ним. В случае с ISR единственно возможный способ обеспечить исключительный доступ к общим переменным - это запрещать прерывания. Если данные разделяются между двумя задачами, каждая из них может получать исключительный доступ к данным либо путём запрещения прерываний, либо посредством семафоров (описаны выше). Нужно заметить также, что задача может сообщать информацию ISR только через глобальные переменные. Задача же не ставится в известность об изменении содержимого глобальных переменных подпрограммой обработки прерывания, если только сама ISR не сигналит задаче посредством семафора, или если только задача регулярно не опрашивает эти переменные. Чтобы исправить эту ситуацию, нужно рассмотреть применение почтовых ящиков или очередей сообщений.
2.24 Почтовые ящики
Почтовый ящик обычно представляет собой переменную-указатель. При помощи предоставляемых ядром сервисов задача или ISR может поместить сообщение (указатель) в этот ящик. Аналогично, одна или более задач могут получать такие сообщения также при помощи сервисов ядра. Отправляющая сообщение и принимающая его задачи должны, конечно, договориться о том, на объект какого типа ссылается этот указатель.
В случае если более чем одна задача желает получать сообщения через данный почтовый ящик, с ним ассоциируется список ожидающих сообщения задач. Задача, желающая получить сообщение из пустого почтового ящика, приостанавливается, и помещается в список ожидающих, до момента действительного поступления сообщения. Также, обычно ядро предоставляет возможность указать величину тайм-аута для ожидающей сообщения задачи. Если сообщение всё же не поступило за указанное время, задача продолжит выполнение, но ей будет сообщён соответствующий код ошибки, указывающий на истечение тайм-аута. Когда сообщение помещено в почтовый ящик, оно сообщается либо ожидающей его задаче с наивысшим приоритетом (приоритетное распределение), либо первой запросившей его задаче ("первый пришёл - первый вышел", First In - First Out, FIFO). На рис. 16 показана задача, помещающая сообщение в почтовый ящик. Почтовый ящик представлен в виде двутавра, а таймаут в виде песочных часов. Число рядом с песочными часами показывает количество тиков системного таймера (обсуждается ниже), которое задача будет ожидать появления сообщения.
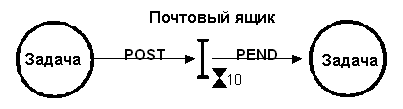
Рис. 2-16, почтовый ящик.
Сервисы ядра обычно позволяют произвести следующие операции с почтовыми ящиками:
а) Инициализировать. Исходно ящик может как содержать, так и не содержать сообщений.
б) Поместить в почтовый ящик сообщения (POST).
в) Ожидать помещения сообщения (PEND).
г) Получить сообщение, если оно есть, но не останавливать вызывающую задачу, если его нет (ACCEPT).
Для оповещения о результате этой операции, задаче сообщается код ошибки.
Почтовые ящики можно использовать для имитации двоичных семафоров. Наличие сообщения в ящике обозначает, что ресурс доступен, а отсутствие показывает, что ресурс уже занят другой задачей.
2.25 Очереди сообщений
Очереди сообщений применяются для передачи более чем одного сообщения. Очередь сообщений обычно представляет собой массив почтовых ящиков. При помощи предоставляемых ядром сервисов задача или ISR может поместить сообщение в очередь. Аналогично, одна или более задач могут получать такие сообщения также при помощи сервисов ядра. Отправляющая сообщение и принимающая его задачи должны, конечно, договориться о том, на объект какого типа ссылается этот указатель. Обычно первое поступившее в очередь сообщение будет и доставлено первым (FIFO), однако микроСи/ОС-II позволяет и обратный порядок доставки ("последний пришёл - первый вышел", Last In - First Out, LIFO).
Как и в случае с почтовым ящиком, если более чем одна задача желает получать сообщения через данную очередь, с ней ассоциируется список ожидающих сообщения задач. Задача, желающая получить сообщение из пустой очереди, приостанавливается, и помещается в список ожидающих, до момента действительного поступления сообщения. Также, обычно ядро предоставляет возможность указать величину тайм-аута для ожидающей сообщения задачи. Если сообщение всё же не поступило за указанное время, задача продолжит выполнение, но ей будет сообщён соответствующий код ошибки, указывающий на истечение тайм-аута. Когда сообщение помещено в очередь, оно сообщается либо ожидающей его задаче с наивысшим приоритетом (приоритетное распределение), либо первой запросившей его задаче ("первый пришёл - первый вышел", First In - First Out, FIFO). На рис. 17 показана ISR, помещающая сообщение в очередь. Очередь представлена в виде двойного двутавра, а таймаут в виде песочных часов. Число 10 показывает количество сообщений, которые могут быть накоплены в данной очереди. Число 0 рядом с песочными часами показывает, что задача будет ожидать появления сообщения бесконечно.
Сервисы ядра обычно позволяют произвести следующие операции с очередями сообщений:
а) Инициализировать. Исходно очередь предполагается пустой.
б) Поместить в очередь сообщение (POST).
в) Ожидать помещения сообщения (PEND).
г) Получить сообщение, если оно есть, но не останавливать вызывающую задачу, если его нет (ACCEPT).
Для оповещения о результате этой операции, задаче сообщается код ошибки.
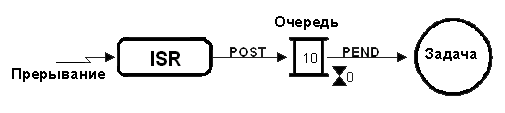
Рис. 2-17, очередь сообщений.
2.26 Прерывания
Прерывания - это аппаратно реализованный механизм, применяемый для информирования процессора об асинхронном поступлении внешних событий. Когда процессор распознаёт прерывание, он сохраняет частично или полностью свой контекст (т. е. регистры), и переходит на специальную подпрограмму, называемую Подпрограммой Обработки Прерывания (Interrupt Service Routine, ISR). Когда прерывание обработано, ISR заканчивается, и процессор возвращается к прежней задаче, то есть:
а) к фоновой задаче, в системе типа "суперпетля";
б) к прерванной задаче, в системе с ядром невытесняющего типа;
в) к задаче с наивысшим приоритетом, в системе с ядром вытесняющего типа.
Механизм прерываний позволяет процессору обрабатывать события по мере их поступления. Это освобождает процессор от необходимости непрерывно опрашивать, например, внешние устройства для определения их готовности. Посредством специальных инструкций отключить прерывания и разрешить прерывания программа может запрещать и разрешать обработку прерываний. В случае системы реального времени, прерывания должны быть отключены минимально возможное время. Отключение прерываний ухудшает время отклика системы (см. раздел 2.27, Латентность прерываний), а также может привести к их потере. Процессоры обычно позволяют вложенные прерывания. Это означает, что в процессе обработки прерывания процессор может распознавать и переходить на обслуживание других, более важных, прерываний, как показано на рис. 2-18.
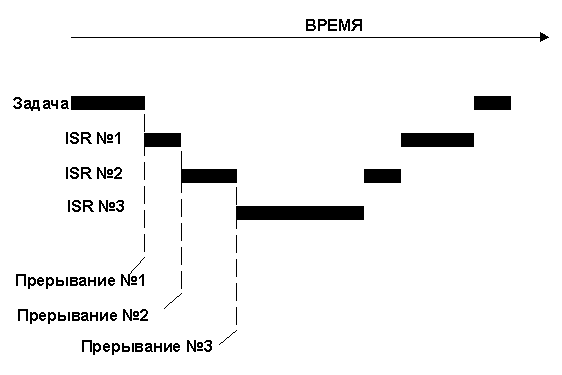
Рис. 2-18, вложенные прерывания.
2.27 Латентность прерываний
Вероятно, самая важная характеристика ядра реального времени - это количество времени, в течение которого прерывания запрещены. Все системы реального времени отключают прерывания перед обработкой критических секций кода, и включают после. Чем дольше прерывания отключены, тем выше латентность прерываний. Латентность прерываний равна:
Максимальное время, которое прерывания запрещены +
Время старта ISR
2.28 Отклик системы на прерывания
Время отклика системы на прерывания определяется как время между моментом распознавания прерывания и моментом начала выполнения фрагмента кода, который это прерывание обслуживает. Время отклика включает в себя все издержки и потери времени, возникающие при обработке прерывания. В частности, обычно перед исполнением собственно кода обработки прерывания процессор сохраняет содержимое своих регистров, т.е. контекст, в области стека.
В системе типа "суперпетля" код обработки прерывания исполняется процессором сразу после сохранения контекста. Время отклика равно:
Латентность прерываний +
Время сохранения контекста
Уравнение 2.3, отклик на прерывания в системе типа "суперпетля".
В системе с ядром невытесняющего типа код обработки прерывания также исполняется процессором сразу после сохранения контекста. Время отклика равно:
Латентность прерываний +
Время сохранения контекста
В случае системы с ядром вытесняющего типа, необходимо вызывать специальную, предоставляемую сервисами ядра, функцию входа в обработчик прерывания. Эта функция оповещает ядро о том, что производится обработка прерывания, и позволяет ядру следить за вложенностью прерываний. В микроСи/ОС-II эта функция называется OSIntEnter(). Время отклика равно:
Латентность прерываний +
Время сохранения контекста +
Время выполнения функции входа в обработчик
В качестве расчётного времени отклика системы на прерывания следует принимать его худшее, то есть максимальное значение. Если система реагирует на прерывания за 50 микросекунд в 99 процентах случаев, и за 250 микросекунд для 1 процента случаев, временем отклика следует считать 250 микросекунд.
2.29 Возврат из прерываний
Временем возврата называется время, которое требуется процессору для возврата к выполнению прерванного кода. В системе типа "суперпетля" для этого требуется восстановить сохранённый в стеке контекст. Время возврата равно:
Время восстановления контекста +
Время выполнения инструкции возврата
В системе с ядром невытесняющего типа также требуется восстановить сохранённый в стеке контекст. Время возврата равно:
Время восстановления контекста +
Время выполнения инструкции возврата
В случае системы с ядром вытесняющего типа ситуация несколько сложней. Обычно, в конце подпрограммы обработки прерывания необходимо вызывать специальную функцию выхода из обработчика прерывания. В микроСи/ОС-II эта функция называется OSIntExit(). Эта функция позволяет ядру следить за вложенностью прерываний. В случае возврата из прерывания низшего уровня к выполнению кода уровня задач, сервисы ядра определяют задачу наивысшего приоритета, находящуюся в состоянии готовности. Если в результате выполнения ISR некая высокоприоритетная задача станет готовой к исполнению, она получит управление процессором. Прерванная же задача, в таком случае, приостанавливается, и получит управление только когда она снова станет самой высокоприоритетной из готовых. Для ядра вытесняющего типа время возврата равно:
Время определения готовности высокоприоритетной задачи +
Время восстановления контекста этой задачи +
Время выполнения инструкции возврата
Уравнение 2.8, возврат из прерываний, ядро вытесняющего типа.
2.30 Латентность прерываний, отклик на прерывания и возврат из прерываний
На рисунках 2-19, 2-20, 2-21 показаны времена латентности прерываний, отклика на прерывания и возврата из прерываний для систем типа "суперпетля", систем с ядром невытесняющего типа и систем с ядром вытесняющего типа соответственно.
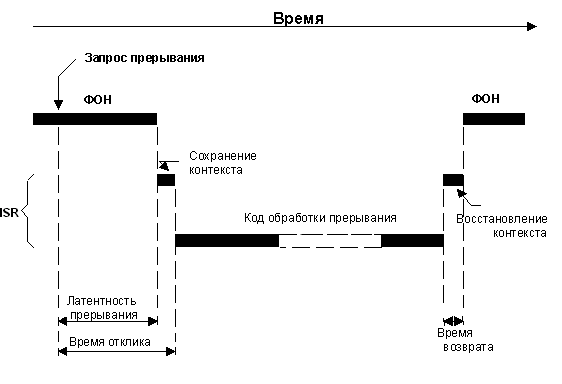
Рис. 2-19, Латентность прерываний, отклик и возврат (для систем типа "суперпетля").
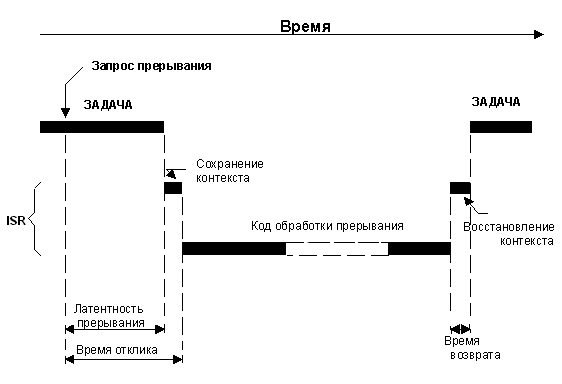
Рис. 2-20, Латентность прерываний, отклик и возврат (для систем с ядром невытесняющего типа).
Необходимо заметить, что в случае ядра вытесняющего типа функция выхода из прерывания решает либо вернуть управление прерванной задаче F2-21A, либо передать управление новой высокоприоритетной задаче F2-21B, которая перешла в состояние готовности в результате отработки ISR. В последнем случае время выполнения функции выхода немного больше, так как ядру необходимо произвести переключение контекста.
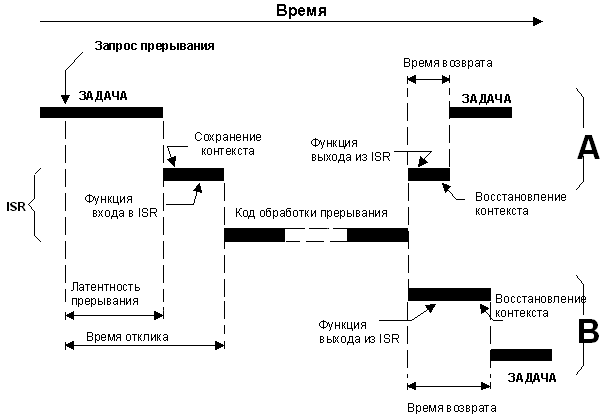
Рис. 2-21, Латентность прерываний, отклик и возврат (для систем с ядром вытесняющего типа).
2.31 Время отработки подпрограммы обслуживания прерывания (ISR)
Хотя ISR должны быть как можно короче, абсолютных пределов длительности ISR не существует. Никто не может сказать, что ISR всегда должна выполняться быстрее, чем за 100 мкс, 500 мкс или 1 мс. Если в ISRрасположен наиболее ответственный код, который должен выполняться всегда за заданное время, то пусть он будет настолько длинным, насколько это необходимо. В большинстве же случаев, конечно, ISR должна распознать прерывание, получить данные или состояние прерывающего устройства, и сигнализировать задаче, которая и займётся собственно обработкой результатов прерывания. Также нужно рассмотреть величину издержек, связанных с сигнализированием, и сравнить их с собственно обработкой прерывания. Сигнализирование задаче из ISR (посредством семафора, почтового ящика или очереди сообщений) требует определённого времени. Если обслуживание прерывания производится быстрее, чем сигнализирование о нём, стоит рассмотреть обработку прерывания в самой подпрограмме обслуживания прерывания, при условии, что прерывания высшего приоритета включены и могут распознаваться и обрабатываться.
2.32 Немаскируемые прерывания (NMI)
Иногда прерывание должно обслуживаться настолько быстро, насколько это возможно, и вообще не иметь латентности, навязываемой обычно ядром. В этом случае вы должны быть готовы использовать так называемое немаскируемое прерывание, NMI, обеспечиваемое большинством микроконтроллеров. Так как немаскируемое прерывание не может быть отключено, латентность, времена отклика и возврата в этом случае минимальны. Обычно немаскируемое прерывание зарезервировано для таких решительных мер, как сохранение важной информации во время сбоя питания. Если, конечно, к вашему приложению не предъявляются такие требования, вы можете задействовать подпрограмму NMI для обслуживания самого критичного ко времени прерывания. Уравнения 2.9, 2.10 и 2.11 показывают соответственно латентность, времена отклика и возврата для случая немаскируемого прерывания.
Время выполнения самой длинной инструкции +
Время старта подпрограммы обслуживания NMI
Уравнение 2.9, время латентности немаскируемого прерывания.
Время латентности +
Время сохранения контекста процессора
Уравнение 2.10, время отклика на немаскируемое прерывание.
Время восстановления контекста процессора +
Время выполнения инструкции возврата
Уравнение 2.11, время возврата из немаскируемого прерывания.
Я использовал NMI в приложении для обслуживания прерывания, могущего возникать каждые 150 микросекунд. Время отработки ISRсоставляло от 80 до 125 микросекунд, причём ядро, которое использовалось, могло запрещать прерывания на время около 45 микросекунд. Очевидно, что если бы я использовал маскируемое прерывание, ISR могла бы опаздывать на 20 микросекунд.
В коде подпрограммы обслуживания NMI нельзя вызывать сервисы ядра для сигнализирования задачам, так как NMI не может быть отключено для возможности доступа к критическим секциям кода. Однако, передача параметров в ISR, а также из ISR немаскируемого прерывания всё же возможна. Для этого параметры должны находиться в глобальных переменных, причём их тип должен позволять обращаться к ним неделимым во времени способом, то есть чтение и запись такой переменой должны производиться за одну инструкцию процессора (а не побайтно, например).
Немаскируемые прерывания можно сделать отключаемыми, добавив внешнюю схему, например такую, как на рис. 2-22. Предположим, что сигнал NMI и сигнал запроса прерывания активны при верхнем уровне, а между источником прерывания и входом NMI процессора имеется вентиль И. Таким образом, немаскируемые прерывания могут быть запрещены записью 0 в порт вывода. Это можно использовать для передачи параметров (например, больших переменных) в, а также из ISR.
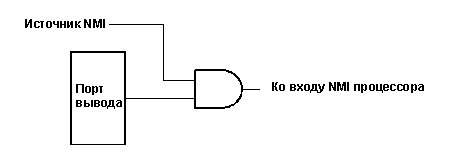
Рис. 2-22, отключение немаскируемого прерывания.
Предположим, что подпрограмма обслуживания NMI должна сигнализировать некоторой задаче каждый сороковой раз своего выполнения. Например, если NMI происходит каждые 150 микросекунд, сигнализировать требуется каждые 6 миллисекунд (40 х 150 мкс). В коде ISR немаскируемого прерывания вы не можете использовать сервисы ядра для сигнализирования задаче, но можно применить схему, показанную на рис. 2-23. В этом случае, подпрограмма обслуживания NMIможет генерировать аппаратное прерывание через порт вывода (переводя его в состояние высокого уровня). Так как ISR NMI обычно имеет высший среди прерываний приоритет, а вложенные немаскируемые прерывания обычно не поддерживаются, данное аппаратное прерывание не будет распознано до окончания ISR немаскируемого прерывания. По завершении же данной процедуры, аппаратное прерывание обнаруживается, и процессор переходит к подпрограмме его обслуживания. Данная ISR может сбросить запрос аппаратного прерывания, переведя порт вывода в состояние низкого уровня, а также сигнализировать требуемой задаче посредством, например, семафора. Если задача справляется с обработкой семафора быстрее, чем за 6 миллисекунд, требования реального времени выполняются.
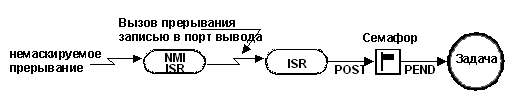
Рис. 2-23, сигнализирование задаче из немаскируемого прерывания.
2.33 Таймерное прерывание
Таймерное прерывание, или прерывание от таймера - это специальное прерывание, регулярное срабатывание которого обеспечивается аппаратно. Таймерное прерывание сродни биению сердца системы. Период срабатывания таймерного прерывания зависит от специфики системы и составляет обычно от 10 до 200 миллисекунд. Таймерное прерывание позволяет ядру задерживать выполнение задач на целое количество периодов таймера и обеспечивать выдержку тайм-аутов задачам, ожидающим возникновения событий. Чем выше темп поступления прерываний от таймера, тем больше затраты процессорного времени в системе (и тем выше точность выдержки интервалов времени - прим. перев.).
Все ядра позволяют приостанавливать выполнение задач на определённое количество периодов таймера. Разрешающая способность по времени, в данном случае, составляет один период таймера, что, конечно, не означает и точность выдержки в один период.
На рисунках с 2-24 по 2-26 показаны временные диаграммы выполнения задачи, задерживающей саму себя на один период таймера. Затемнённые фрагменты показывают время выполнения каждой операции. Обратите внимание, что времена показаны разными для каждой операции, что отражает обычный ход выполнения, которое может включать в себя петли и условные операторы (такие как if/else, switch, ?:). Время выполнения таймерного прерывания показано преувеличенным .
В первом случае, на рис. 2-24, показана ситуация, когда высокоприоритетные задачи и ISR выполняются до задачи, желающей задержать своё выполнение на 1 период таймера. Как видно, задача пытается задерживаться на 20 мс, но, имея данный приоритет, она фактически выполняется через изменяющиеся интервалы. Такие отклонения от строгой регулярности выполнения называются джиттером.
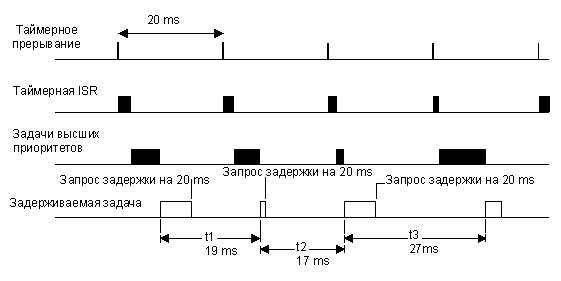
Рис. 2-24, задержка выполнения на 1 период таймера (случай №1).
Во втором случае, на рис. 2-25, показана ситуация, когда время выполнения всех высокоприоритетных задач и ISR немного меньше одного периода системного таймера. Если задача попытается задержать себя на 1 период таймера перед самым его срабатыванием, она фактически почти сразу же продолжит выполнение! Поэтому, если необходимо задержать задачу, по крайней мере, на 1 период таймера, следует назначить ещё один дополнительный период. Другими словами, если нужно задержать задачу на пять периодов таймера, вы должны указать шесть!
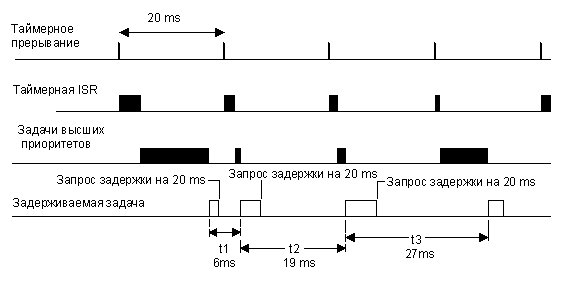
Рис. 2-25, задержка выполнения на 1 период таймера (случай №2).
В третьем случае, на рис. 2-26, показана ситуация, когда время выполнения всех высокоприоритетных задач и ISRбольше, чем период таймера. В этом случае, задача, попытавшаяся задержать своё выполнение на 1 период, на самом деле продолжит выполнение двумя периодами позже. Таким образом, задача пропускает крайний срок своего выполнения и не вписывается в требования жесткого реального времени. Иногда это допустимо, но в большинстве случаев нет.
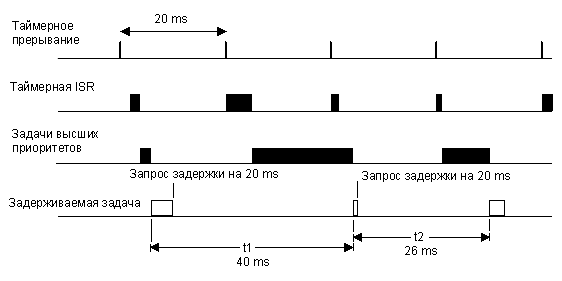
Рис. 2-26, задержка выполнения на 1 период таймера (случай №3).
Такие ситуации возникают во всех системах реального времени. Они связаны с величиной загрузки процессора и, иногда, с некорректным построением системы. Возможны следующие решения этой проблемы:
а) повысить тактовую частоту микропроцессора
б) увеличить время между таймерными
прерываниями
в) перераспределить приоритеты
задач
г) избегать вычислений с плавающей
точкой (или применять одинарную точность)
д) использовать лучшую оптимизацию
кода
е) написать критичные куски кода
на ассемблере
ж) перейти на старший процессор
того же семейства, то есть с 8086 на 80186, с 68000 на 68020, и т.д.
Однако это не ликвидирует джиттер полностью.
2.34 Требования к памяти
Если вы проектируете систему типа "суперпетля", количество требуемой памяти полностью зависит от вашего приложения.
Для многозадачного ядра всё немного по-другому. Начнём с того, что требуется дополнительный объём памяти программ для его размещения. Размер ядра зависит от многих факторов. В зависимости от количества сервисов, обеспечиваемых ядром, можно ожидать объёма где-то от 1 Кбайта до 100 Кбайт. Небольшое ядро для 8-разрядного микропроцессора, поддерживающее только диспетчеризацию, переключение контекста, управление семафорами, задержки и тайм-ауты, должно требовать от 1 до 3 Кбайтов памяти программ. Полный объём памяти программ равен:
Размер кода приложений +
Размер кода ядра
Так как каждая задача выполняется независимо от других, она должна иметь собственный стек в ОЗУ. Как проектировщик, вы должны определить требуемый размер стека каждой задачи настолько точно, насколько это возможно (иногда это непросто). Размер стека должен учитывать не только требования задачи (такие как локальные переменные, вызовы функций, и т.п.), но и обработку прерываний максимальной степени вложенности (сохранение регистров, локальные данные в ISR и т.д.). В зависимости от процессора и используемого ядра, для кода подпрограмм обработки прерываний возможно применение отдельного стека. Это весьма желательно, так как уменьшает требования к глубине стека каждой задачи. Другой желательной чертой является возможность задавать глубину стека индивидуально для каждой задачи (микроСи/ОС-II это позволяет). Некоторые ядра, наоборот, требуют, чтобы размер стека был одинаков для всех задач. Однако все ядра требуют дополнительный объём памяти для хранения внутренних переменных, структур данных, очередей и проч. Если система не поддерживает отдельный стек для ISR, полный объём памяти равен:
Память данных приложений +
Память данных ядра +
SUM( размер стеков всех задач + MAX( глубина вложенности ISR))
Если отдельный стек для ISR поддерживается, полный объём памяти равен:
Память данных приложений +
Память данных ядра +
SUM( размер стеков всех задач) +
MAX(глубина вложенности ISR)
Необходимо быть внимательным с тем, как используется область стека, если только вы не имеете большого количества свободной памяти. Чтобы уменьшить необходимое приложению количество памяти, необходимо проследить за использованием стеков каждой задачи для:
а) больших массивов и структур,
объявленных локально в функциях и ISR
б) поддержки вложенных функций
в) поддержки вложенных прерываний
г) библиотечных функций
д) вызовов функций со многими аргументами
Подводя итоги, можно сказать, что многозадачная система потребует большего количества памяти программ (ПЗУ) и памяти данных (ОЗУ), нежели система типа "суперпетля". Количество дополнительного ПЗУ зависит только от размера самого ядра, а количество дополнительного ОЗУ - от числа задач в системе.
2.35 Преимущества и недостатки ядер реального времени
Ядро реального времени, также называемое операционной системой реального времени, или ОСРВ, позволяет проектировать и легко расширять приложения реального времени; дополнительные функции могут быть добавлены без существенных изменений в программном обеспечении. Применение ОСРВ позволяет упростить процесс проектирования за счёт разбиения кода приложения на отдельные задачи. Вытесняющая ОСРВ поддерживает все критичные ко времени события так быстро и эффективно, насколько это возможно. ОСРВ позволяет лучше использовать имеющиеся ресурсы, обеспечивая такие ценные сервисы как семафоры, почтовые ящики, очереди, задержки, тайм-ауты и другие.
Вы должны рассмотреть возможность применения ядра реального времени в вашем приложении, если можно использовать больше ПЗУ/ОЗУ, от 2 до 4 процентов процессорного времени, а также вас устраивает цена самого ядра. В некоторых случаях, цена - это всё, и это может помешать использовать ОСРВ.
На современном этапе имеется
80 с лишним производителей ОСРВ для 8-ми, 16-ти и 32-х разрядных микропроцессоров.
Некоторые из этих продуктов представляют собой полные операционные системы
и включают в себя не только ядро реального времени, но также и менеджер ввода/вывода,
систему графического интерфейса, файловую систему, поддержку сети, библиотеки
поддержки языков программирования, отладчики и кросс-компиляторы. Цены ОСРВ
разнятся от 50 долларов до 30 тыс. долларов и выше. Производитель ОСРВ может
также потребовать выплат с каждого проданного экземпляра вашего устройства.
Это похоже на покупку микросхемы у её производителя. Выплаты могут составлять
от 5 до 250 долларов с устройства. Как и со всяким программным обеспечением
в наши дни, потребуются дополнительные расходы на его поддержку, которые могут
составить от 100 до 5 тыс. долларов в год!